Conjuntos de Caracteres HTML
Aprenda os conjuntos de caracteres HTML — ASCII, ANSI, ISO-8859-1 e UTF-8 — e como declarar a codificação com a meta tag charset para exibir páginas corretamente.
Um conjunto de caracteres (ou codificação de caracteres) é o mapeamento que informa ao navegador como converter os bytes brutos de um arquivo nas letras, dígitos, pontuação e símbolos que você vê na tela. O navegador precisa saber qual conjunto de caracteres uma página usa para exibi-la corretamente.
UTF-8 é a codificação de caracteres padrão para o HTML5. Nem sempre foi assim. O ASCII veio primeiro, e o ISO-8859-1 foi o conjunto de caracteres padrão do HTML 2.0 ao HTML 4.01. Cada um desses conjuntos mais antigos conseguia representar apenas um intervalo limitado de caracteres, o que causava problemas com textos em outros idiomas além do inglês. Quando o UTF-8 chegou junto com o HTML5 e o XML, resolveu a maioria desses problemas ao cobrir praticamente todos os sistemas de escrita em uma única codificação.
Esta página percorre os principais conjuntos de caracteres que você pode encontrar — ASCII, ANSI, ISO-8859-1 e Unicode/UTF-8 — e mostra como declarar a codificação tanto em HTML moderno quanto em HTML legado.
O que dá errado quando a codificação está ausente ou incompatível
Se uma página não declara sua codificação, ou declara uma que não corresponde à forma como o arquivo foi realmente salvo, o navegador adivinha — e frequentemente erra. O sintoma mais comum é o mojibake: texto ilegível onde letras acentuadas, aspas curvas ou emoji se transformam em sequências como é ou ’.
Além de parecer quebrado, um charset não declarado ou incompatível pode ser uma preocupação de segurança: alguns ataques dependem do navegador interpretar bytes sob uma codificação diferente da pretendida pelo autor (por exemplo, cross-site scripting baseado em UTF-7). Declarar uma codificação única e explícita de antemão elimina essa ambiguidade. A escolha segura e moderna é sempre servir conteúdo como UTF-8 e afirmar isso claramente com <meta charset="UTF-8">.
ASCII
O ASCII foi o primeiro padrão de codificação de caracteres, também chamado de conjunto de caracteres. É a abreviação de American Standard Code for Information Interchange.
Para cada caractere armazenável, o ASCII definiu um número único para suportar o alfabeto em maiúsculas e minúsculas (a-z, A-Z), os números 0-9 e um conjunto de caracteres especiais. É baseado no alfabeto inglês e codifica 128 caracteres em um inteiro binário de 7 bits. Por exemplo, a letra maiúscula A tem o código 65 (binário 01000001), a tem 97 e o dígito 0 tem 48. Isso funciona porque toda informação computacional é, em última análise, registrada como uns e zeros binários na eletrônica.
Abaixo, você pode ver uma tabela ASCII mapeando cada caractere para seu código decimal, hexadecimal e binário.
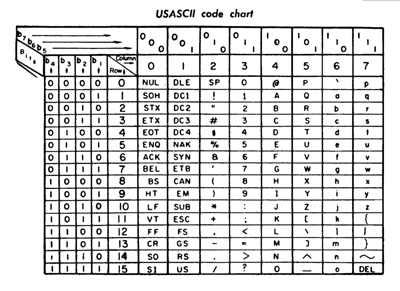
A maior limitação do ASCII é que ele não possui letras não inglesas nem caracteres acentuados. Ainda está em uso hoje, especialmente em computadores de grande porte, e forma a base sobre a qual codificações posteriores (incluindo UTF-8) foram construídas.
Clique aqui para saber mais sobre ASCII.
ANSI
O ANSI, também chamado de Windows-1252, foi o conjunto de caracteres padrão do Windows até o Windows 95. É uma extensão do ASCII que adiciona caracteres internacionais. Ele suportava 256 caracteres usando um byte completo (8 bits).
O ANSI era suportado por todos os navegadores desde que foi anunciado como o conjunto de caracteres padrão do Windows.
ISO-8859-1
O ISO-8859-1 tornou-se a codificação de caracteres padrão no HTML 2.0, pois a maioria dos países usa caracteres diferentes dos do ASCII. Também é uma extensão do ASCII, assim como o ANSI, e adiciona caracteres internacionais. O ISO-8859-1 também usa um byte completo para representar o dobro de caracteres em relação ao ASCII.
Clique aqui para saber mais sobre ISO-8859-1.
Codificação padrão do HTML 4
No HTML 4, a codificação era declarada com uma tag <meta> http-equiv. Como o ISO-8859-1 era o padrão, era assim que você o declarava explicitamente:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1" />Substituindo o charset no HTML 4
Se uma página HTML 4 precisar de uma codificação de caracteres diferente do padrão ISO-8859-1 — por exemplo, ISO-8859-8 para hebraico — basta alterar o valor charset na mesma tag <meta>:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-8" />A maioria dos processadores HTML 4 também entendia UTF-8, o que abriu caminho para ele se tornar o padrão no HTML5.
O modo HTML5
O HTML5 substituiu a forma verbosa http-equiv por um atributo curto e dedicado:
<meta charset="UTF-8" />Coloque essa tag o mais cedo possível dentro do elemento <head> — idealmente como o primeiro filho — para que o navegador leia a codificação antes de analisar qualquer conteúdo de texto.
Unicode UTF-8
O UTF-8 é a codificação de caracteres padrão — e recomendada — para o HTML5.
Como os conjuntos de caracteres descritos acima estão limitados a no máximo 256 caracteres, o Unicode Consortium desenvolveu o Padrão Unicode, um catálogo único que atribui um número exclusivo (chamado de code point) a quase todos os caracteres, sinais de pontuação e símbolos usados no mundo — em milhares de idiomas, além de emoji e símbolos matemáticos. O UTF-8 é a forma mais popular de codificar esses code points como bytes.
Por que UTF-8 é o padrão moderno
Três propriedades tornam o UTF-8 a escolha natural para a web:
- Cobertura universal. Ele pode representar todo code point Unicode, de modo que uma única página pode misturar inglês, árabe, chinês e emoji sem precisar trocar de codificação.
- Compatível com ASCII. Os primeiros 128 code points são codificados exatamente com os mesmos bytes únicos que o ASCII. Qualquer arquivo ASCII simples já é UTF-8 válido, o que significa que décadas de textos e ferramentas mais antigas continuam funcionando.
- Eficiência de largura variável. Caracteres comuns ocupam apenas um byte, enquanto os menos comuns usam dois, três ou quatro bytes apenas quando necessário. Documentos predominantemente em inglês permanecem compactos, mas nada fica de fora.
Em HTML, o atributo charset na tag <meta> especifica a codificação:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>UTF-8 example</title>
</head>
<body>
<p>English, Русский, 中文, العربية, 😀</p>
</body>
</html>Mantenha <meta charset="UTF-8"> como o primeiro elemento no <head> (dentro dos primeiros 1024 bytes do documento). Se vier tarde demais, o navegador pode começar a analisar o texto com a codificação errada antes de ver a declaração.
Caracteres multibyte e o BOM
Em UTF-8, um único caractere pode abranger vários bytes. Por exemplo, o símbolo do euro € (code point Unicode U+20AC) é armazenado como os três bytes E2 82 AC, enquanto um caractere como A ainda ocupa apenas um byte. É isso que "largura variável" significa na prática.
Você também pode se deparar com o BOM (Byte Order Mark), uma sequência invisível opcional de bytes (EF BB BF para UTF-8) no início de um arquivo que sinaliza sua codificação. Um BOM não é necessário para UTF-8 e geralmente é melhor omiti-lo em HTML, pois um <meta charset="UTF-8"> explícito já cumpre essa função, e um BOM indevido pode ocasionalmente causar problemas de renderização.
Para inserir símbolos específicos sem se preocupar com como seu editor salva o arquivo, você também pode usar entidades HTML com nomes ou numéricas (por exemplo, € para €).
Todos os processadores HTML5 suportam UTF-8. Note que os processadores XML exigem estritamente UTF-8 ou UTF-16.